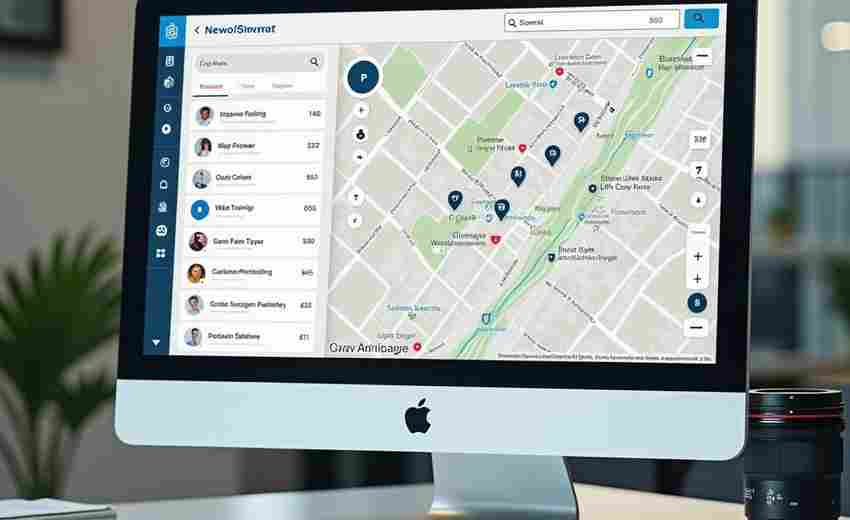
在谷歌SEO中,robots.txt和站点地图分别承担着不同的技术管理角色,二者协同作用可优化搜索引擎抓取效率和索引质量。以下是其核心作用及实践要点:
一、Robots.txt的核心作用
1. 控制爬虫访问权限
通过指定允许或禁止抓取的目录和文件,避免重复内容、测试页面、后台路径等低价值或敏感页面被索引。例如,阻止爬虫访问`/admin/`或`/tmp/`路径可减少无效索引。
2. 优化搜索引擎抓取预算
搜索引擎对单个网站的抓取资源有限(抓取预算)。通过robots.txt屏蔽低优先级页面,可将爬虫资源集中在核心内容上,提升重要页面的索引速度和频率。
3. 降低服务器资源消耗
限制爬虫对非关键页面的请求,可减少服务器负载,间接提升网站响应速度,改善用户体验。
4. 规避敏感信息泄露风险
例如临时促销页面、内部系统入口等无需公开的内容,可通过robots.txt直接阻止抓取,降低被索引的可能性。
二、站点地图(Sitemap)的核心作用
1. 加速新页面索引
提供网站所有页面的结构化列表,帮助搜索引擎快速发现新增或更新内容,尤其对内容量大、层级复杂的网站至关重要。
2. 解决抓取遗漏问题
通过XML站点地图明确列出深层次页面(如无内链引用的独立页面),减少爬虫因网站结构问题导致的抓取盲区。
3. 设定页面优先级与更新频率
XML站点地图支持标注页面权重(`4. 支持多语言与多媒体内容优化
站点地图可标注不同语言版本的页面或视频、图片等多媒体文件,帮助搜索引擎理解内容关系,提升多类型资源的索引效果。
三、协同使用建议
互补性策略:robots.txt用于“限制”,站点地图用于“引导”。例如,用robots.txt屏蔽无关路径的通过站点地图主动推送核心页面。
技术规范:
robots.txt需放置在网站根目录(如`/robots.txt`),避免语法错误导致意外屏蔽。
XML站点地图需提交至Google Search Console,并定期更新以反映内容变化。
替代方案:若需完全阻止页面被索引,建议使用`noindex`标签而非仅依赖robots.txt,因为后者仅控制抓取,不直接阻止索引。
通过以上组合策略,可显著提升网站在谷歌要求中的可见性与内容质量。